What does data quality even mean?
One of the less discussed, but equally important, reasons data quality is so hard to own is deceptively simple: data quality (and ownership of it) means different things to different people.
Data quality in a technical sense is often boiled down to a checklist of dimensions — freshness, completeness, consistency, distribution, validity, and uniqueness. These six pillars are frequently referenced in frameworks, and while useful in some sense, they only describe a part of the picture. That’s where the disconnect starts.
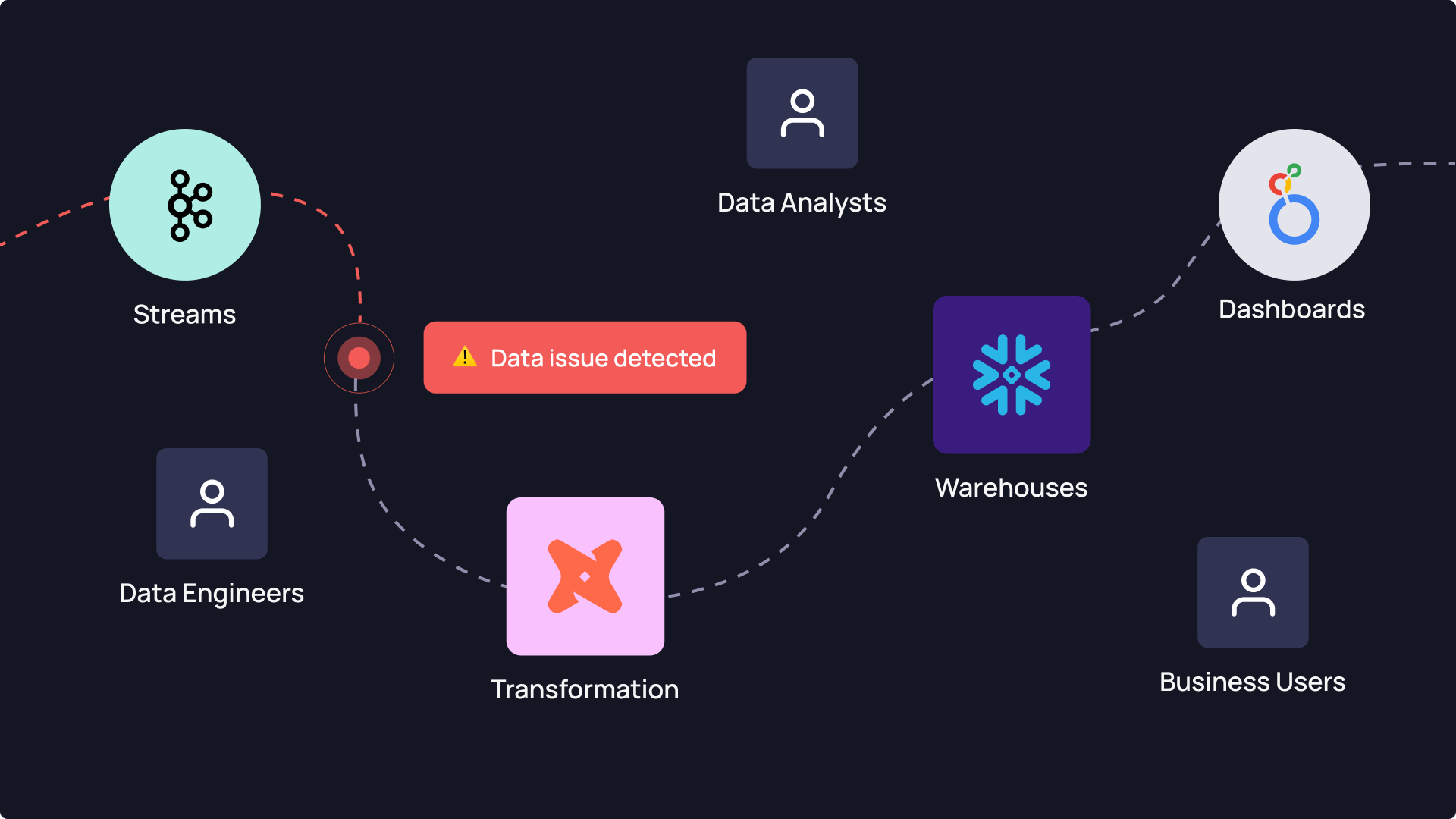
Data issues can emerge anywhere in the pipeline: from collection and ingestion, to transformation and transportation, and finally: at consumption. Each stage has its own stakeholders with different needs and definitions of what quality looks like:
- At the ingestion stage, data engineers tend to focus on freshness (is the data arriving on time?), validity (does it match the expected schema?), and completeness (are all expected records present?). If those checks pass, the data is labeled “high quality.”
- But as the data moves downstream into the transformation layer, where it’s joined with other sources and reshaped into business-friendly tables, new expectations surface. Distribution suddenly matters. Outliers might suggest broken logic or faulty assumptions. And consistency becomes critical: are fields aligned across datasets? Does a customer ID mean the same thing across the board?
- Finally, in the consumption layer, where dashboards, metrics, and machine learning outputs are created, quality takes on yet another form. Business users typically assume that the data is complete and fresh by default. Their concern is with accuracy in the metrics, reliability of trends, and whether the data makes sense. They’re operating at a level where even subtle shifts in data distribution can undermine trust, but they don’t have visibility into upstream issues.
This mismatch in expectations leads to a classic situation: a data engineer sees the data as high quality because all ingestion checks passed. Meanwhile, a business stakeholder opens their dashboard and sees a 30% drop in monthly revenue — and immediately declares the data “broken.”
Both perspectives are valid. And that’s the problem.
Without a shared understanding of what data quality really means — across the full pipeline — it becomes nearly impossible to define ownership or enforce accountability. Everyone’s measuring quality through their own lens. No one’s aligned on what matters most.